utf-8-merkkinen koodaus
Unicode tukee lähes kaikkia olemassa oleviamerkistöjä. Unicode-merkistökoodin paras muoto on utf-8-koodaus. Se tarjoaa yhteensopivuuden ASCII: n kanssa, vastustaa tietojen korruptiota, tehokkuutta ja helppokäyttöisyyttä. Mutta kaikesta kunnossa.
Koodauksen muodot
Tietokoneet toimivat numeroiden kanssa ei vainabstrakteja matemaattisia esineitä, mutta kiinteiden kokoisten tietojen tallennus- ja käsittelyyksiköiden yhdistelmiä - tavua ja 32-bittisiä sanoja. Koodausstandardin on otettava tämä huomioon määrittäessään merkkien merkitsemistä numeroilla.
Tietokonejärjestelmissä kokonaislukuja tallennetaan sisäänmuistisoluja, joiden koko on 8 bittiä (1 tavua), 16 tai 32 bittiä. Kukin Unicode-koodausmuoto määrittää, mikä muistisolujen sekvenssi edustaa tietyn merkin vastaavaa kokonaislukua. Standardi tarjoaa kolme eri muotoa Unicode-merkkien koodausta varten: 8, 16 ja 32-bittiset lohkot. Niinpä niitä kutsutaan utf-8: ksi, UTF-16: ksi ja UTF-32: ksi. Nimi UTF tarkoittaa Unicode-muunnosmuotoa. Jokainen kolmesta koodausmuodosta on yhtä suuri keino esittää Unicode-merkkejä, sillä on etuja useissa sovelluksissa.
Näitä koodauksia voidaan käyttääedustaa kaikkia Unicode-merkkejä. Niinpä ne ovat täysin yhteensopivia ratkaisuista eri syistä erilaisten koodausmuotojen avulla. Jokainen koodaus voidaan muuttaa yksitellen mihinkään muuhun kahdesta ilman datan menetystä.

Määräämättä jättämisen periaate
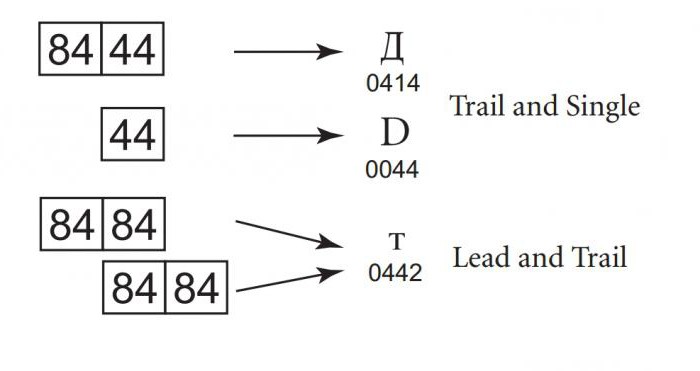
Kukin Unicode-koodauslomake on suunniteltuottaen huomioon osittaisten päällekkäisyyksien tutkimatta jättäminen. Esimerkiksi Windows-932 luo merkkejä yhdestä tai kahdesta tavusta koodista. Jakson pituus riippuu ensimmäisestä tavusta, joten kahden tavun ja yhden tavun johtavat tavut arvot eivät leikkaa toisiaan. Kuitenkin yhden tavun ja sekvenssin viimeisen tavun arvot voivat olla samat. Tämä tarkoittaa esimerkiksi sitä, että etsittäessä merkkiä D (koodi 44) voit virheellisesti löytää sen tulleen merkille "D" (koodi 84 44) kahden tavun sekvenssin toiseen osaan. Jotta määritettäisiin, mikä sekvenssi on oikea, ohjelmassa on otettava huomioon edelliset tavut.
Tilanne muuttuu entistä monimutkaisemmaksi, jos johtava ja jäljessä olevatavut vastaavat. Tämä tarkoittaa sitä, että epäselvyyden kääntämiseksi suoritetaan käänteinen haku tekstin alkuun tai koodin yksiselitteiseen jaksoon saakka. Tämä ei ole vain tehoton, mutta ei suojattu mahdollisia virheitä vastaan, koska yksi huono tavu riittää tekemään koko tekstin lukemattomaksi.
Unicode-muunnosmuoto välttäätämän ongelman vuoksi, koska johtavan, sulkeutuvan ja yksittäisen tiedon tallennusyksikön arvot eivät täsmää. Tästä johtuen kaikki Unicode-koodaukset soveltuvat etsintään ja vertailemiseen, eivätkä koskaan anna virheellistä tulosta johtuen merkkikoodin eri osien yhteensopivuudesta. Se tosiasia, että nämä koodausmuodot noudattavat periaatetta, joka ei ole osoitettu, erottaa ne muista monitiheyksistä Itä-Aasian koodauksista.
Toinen näkökulma Unicode-koodausten ei-leikkauskohdastaon, että jokaisella merkillä on selkeästi määritellyt rajat. Tämä poistaa tarpeen tarkistaa määrittelemätön määrä aiempia merkkejä. Tätä koodausominaisuutta kutsutaan joskus itsesynkronoinniksi. Yksittäisen koodin vääristyminen johtaa vain yhden merkin vääristymiseen, ja ympäröivät merkit pysyvät ennallaan. Jos 8-bittinen muunnosmuoto, jos osoitin viittaa tavuun, joka alkaa 10xxxxxx (binaarikoodauksella), merkin alun löytämiseksi tarvitaan yksi tai kolme käänteistä siirtymää.
johdonmukaisuus
Unicode Consortium tukee täysin kaikkia3 koodausta. On tärkeää olla vastustamatta utf-8: ta ja Unicodea, koska kaikki muunnosmuodot ovat yhtä laillisia Unicode-merkkikoodauslomakkeiden toteutuksia.
Tavu-orientaatio
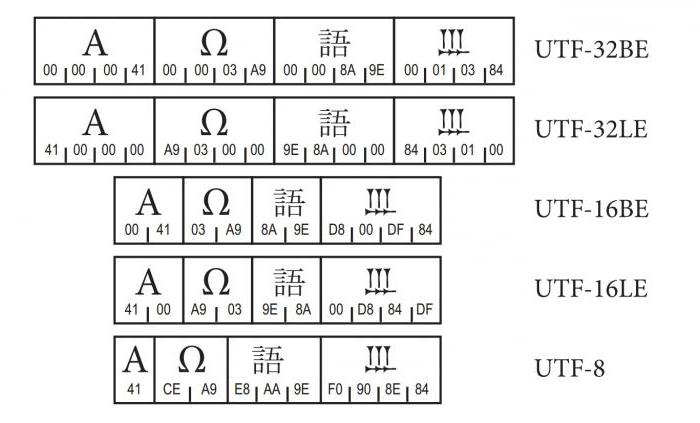
UTF-32-symbolin kuvaamiseksi tarvitset yhden 32-bittisen koodin yksikön, joka vastaa Unicode-koodia. UTF-16 - yhdestä kahteen 16-bittiseen yksikköön. Utf-8 käyttää jopa 4 tavua.
Koodaus utf-8 luotiin yhteensopivuuden kanssabyte-suuntautuvat järjestelmät, jotka perustuvat ASCII-järjestelmään. Suurin osa olemassa olevista ohjelmisto- ja tietotekniikan käytänteistä on pitkään luotu symbolien esittämiseen tavun tavujen muodossa. Monet protokollat riippuvat muuttumattomasta ASCII-koodauksesta ja joko käyttävät tai välttävät erityisiä ohjausmerkkejä. Helppo tapa mukauttaa Unicode tällaisiin tilanteisiin on käyttää 8-bittistä koodausta edustamaan Unicode-merkkejä, jotka vastaavat mitä tahansa ASCII-merkkiä tai ohjausmerkkiä. Tätä varten utf-8-koodaus on tarkoitettu.
Muuttuva pituus
utf-8 on muuttuvan pituinen koodaus, joka koostuu8-bittinen varastointiyksiköt, ylempi bittiä, jotka osoittavat, mikä osa sekvenssin kunkin tavun kuuluu. Yksi arvojen varattu ensimmäinen osa koodisekvenssin, toinen - seuraavan. Tämä varmistaa disjoint-koodauksen.
ASCII
utf-8-koodaus tukee täysin ASCII-koodeja(0x00-0x7F). Tämä tarkoittaa, että Unicode-merkkejä U + 0000-U + 007F muunnetaan yhdeksi tavuksi 0x00-0x7F utf-8 ja näin ollen erotetaan ASCII: sta. Lisäksi epäselvyyden välttämiseksi arvoja 0x00-0x7F ei enää käytetä Unicode-merkin esitystavoissa. Muiden kuin ideografisten symbolien koodaamiseksi kuin ASCII: ssä käytetään kahden tavun jaksoa. U + 0800-U + FFFF: n symboleja edustaa kolme tavua, ja lisäksi U + FFFF-koodeilla suuremmat koodit vaativat neljä tavua.
Soveltamisala
Koodaus utf-8 on yleensä edullinen HTML-protokollassa ja sen kaltainen.
XML tuli ensimmäinen standardi, jossa oli täysi tukikoodaukset utf-8. Myös standardointiin osallistuvat organisaatiot suosittelevat sitä. tuki ongelma URL-osoitteen, joka on erilainen kuin ASCII-merkkejä, ratkesi kun konsortio W3C ja IETF suunnittelukonserneja pääsivät sopimukseen koodaukseen kaikkien URL-osoitteiden yksinomaan UTF-8.
Yhteensopivuus ASCII: n kanssa helpottaa siirtymistä uuteenohjelmisto. Utf-8: n avulla useimmat tekstin toimittajat toimivat, mukaan lukien JEdit, Emacs, BBEdit, Eclipse ja Notepad Windows-käyttöjärjestelmästä. Mikään muu Unicode-koodauksen muoto ei voi ylpeillä työkalujen tuesta.
Koodauksen etu on, että sekoostuu tavun tavuista. Utf-8-merkkijonoilla on helppo työskennellä C: ssä ja muissa ohjelmointikielissä. Tämä on ainoa koodausmuoto, joka ei vaadi BOM-tavujen tai XML-koodausilmoituksen merkitsemistä.

self-synkronointi
8-bittisessä merkkikäsittelyssä käyttävässä ympäristössä, verrattuna muihin monitavuisiin koodauksiin, utf-8: lla on seuraavat edut:
- Koodisekvenssin ensimmäisellä tavulla on tietoja sen pituudesta. Tämä lisää suorahaun tehokkuutta.
- Merkin alkua on helpompi löytää, koska alkuperäinen tavu on rajoitettu kiinteään arvoalueeseen.
- Ei ole tavujen arvojen leikkauspisteitä.
Etujen vertailu
utf-8-koodaus on kompakti. Mutta kun haetaan Itä-Aasian merkkien koodaamista (kiina, japani, korea, käyttäen kiinalaisia merkkejä) käytetään 3 tavun sekvenssejä. Myös utf-8-koodaus on huonompi kuin muut koodausmuodot käsittelynopeudella. Binaarisarjan lajittelu tuottaa saman tuloksen kuin Unicode-binääriluokka.
Merkkikoodausjärjestelmä
Merkkikoodausjärjestelmä koostuu lomakkeestamerkkikoodauksen ja koodijoukon byte-by-pixel -järjestelyn menetelmällä. Kun koodausjärjestelmä on määritetty Unicode-standardilla, annetaan alustavan tavujärjestysmerkin (BOM, Byte-tilausmerkki) käyttö.
Kun BOM on otettu käyttöön utf-8: ssä, tarrafunktioon rajoitettu vain ilmoittamalla koodauslomakkeen käytöstä. Ongelmia ei ole määritellä utt-8: n tavun tavuilla, koska sen koodausyksikön koko on yksi tavu. Tämän koodauslomakkeen käyttö ei ole pakollinen eikä suositeltava. BOM voi esiintyä muissa koodauksissa muunnetuissa teksteissä, jotka käyttävät tavujärjestysmerkin tai utf-8-koodaussignaalin. Se on 3 tavun EF-sarja16 BB16 BF16.
Miten määrität utf-8-koodauksen
HTML: ssä utf-8-koodaus on asetettu seuraavalla koodilla:
pää
˂meta http-equiv = "Sisältötyyppi" content = "teksti / html; charset = utf-8" ˂
PHP: ssä utf-8 -koodaus määritetään otsikon () -toiminnon avulla tiedoston alussa, kun virheentotason arvo on asetettu:
˂? Php
error_reporting (-1);
otsikko ("Sisältötyyppi: teksti / html; charset = utf-8");
Yhteyden muodostaminen MySQL-tietokantoihin utf-8-koodaus on asetettu seuraavasti:
˂? Php
mysql_set_charset ("utf8");
CSS-tiedostoa merkkikoodausta utf-8 ilmaistaan seuraavasti:
@charset "utf-8";
Kun tallennat kaikentyyppisiä tiedostoja, valitsekoodaus utf-8 ilman BOM, muuten sivusto ei toimi. Tätä varten DreamWeave-ohjelmassa sinun on valittava valikkokohta "Muutokset - Sivun ominaisuudet - Otsikko / koodaus", vaihda koodaus utf-8: ksi. Sitten sinun on ladattava sivu uudelleen, poista valinta "Connect Unicode Signatures (BOM)" -kohdasta ja käytä muutoksia. Jos sivun tai tietokannan teksti on syötetty toisella koodauslomakkeella, se on syötettävä uudelleen tai uudelleen koodattava. Kun käytät säännöllisiä lausekkeita, on pakollista käyttää u-modifiointia.
Voit myös tallentaa tiedoston utf-8-koodaukseen Windows Notepadissa. Kun olet valinnut valikkokohdan "Tiedosto - Tallenna nimellä ...", aseta tarvittava koodauslomake ja tallenna tiedosto utf-8-koodaukseen.
Jos Notepad ++ -teksteditorissa, jos koodaus poikkeaa utf-8: sta, muuta koodausta ja tallenna se utf-8-koodaukseen valikkokohdan "Muunna utf-8 ilman BOM" kautta.

Ei ole vaihtoehtoa
Globalisaation yhteydessä, kun poliittinen jakieliresurssit poistetaan, symbolien sarjat, joilla on paikallisia ominaisuuksia, tulevat vähemmän hyödyllisiksi. Unicode on ainoa merkistö, joka tukee kaikkia lokalisointeja. Ja utf-8 on esimerkki Unicoden oikeasta toteutuksesta, joka:
- tukee laajaa valikoimaa työkaluja, mukaan lukien yhteensopivuus ASCII-koodauksen kanssa;
- vastustaa tietojen korruptiota;
- yksinkertainen ja tehokas käsittely;
- ei riipu alustasta.
Kun julkaisussa utf-8 on keskusteltu siitä, minkälainen koodaus tai merkistö on parempi, heistä tuli merkityksettömiä.








